
Have you ever wondered what powers those stunning visuals in your favorite games or the lightning-fast computations behind AI models?
It’s all thanks to GPUs or Graphics Processing Units. But what exactly makes these chips so powerful? And how does their architecture differ from the processors running your everyday tasks?
If you’re curious about how GPUs handle the most demanding workloads, from gaming to deep learning, you’re in the right place. Understanding the fundamentals of GPU architecture can help you make informed decisions, whether you’re a gamer, a developer, or simply tech-savvy.
In this guide, we’re breaking down everything you need to know about GPU architecture—no overly complex jargon, just clear explanations.
We’ll explore how GPUs have evolved, what makes them different from CPUs, and why their architecture is key to handling massive data processing tasks.
By the end of this, you’ll have a solid grasp of how modern GPUs are shaping the future of technology, from cloud computing to AI acceleration.
So, let’s dive in and discover what makes GPUs the backbone of today’s high-performance computing!
What is GPU Architecture?
In simple terms, GPU architecture refers to the structure and design of a Graphics Processing Unit. It’s essentially how the internal components of a GPU are arranged to optimize its performance. Unlike CPUs (Central Processing Units) that focus on executing sequential tasks, GPUs are built to handle massive amounts of data simultaneously through parallel processing. This makes them incredibly efficient at tasks like gaming graphics, AI training, and data visualization.
But what exactly goes into GPU architecture? Let’s break it down to understand its purpose, components, and how it has evolved.
CPU & GPU Architecture: Differences and Similarities
When we compare a Central Processing Unit (CPU) and a Graphics Processing Unit (GPU), one of the primary differences lies in their approach to processing tasks. A CPU is designed to minimize latency, focusing on completing tasks as quickly as possible with minimal delay.
It achieves this by processing tasks serially, one at a time, while also having the flexibility to switch between operations efficiently. This low-latency processing is crucial for tasks that require high single-threaded performance, like running system operations and handling complex logic.
On the other hand, a GPU is built for throughput optimization. Instead of focusing on completing one task at a time, a GPU can handle a large number of tasks simultaneously through parallel processing.
This architecture allows the GPU to push as many tasks through its internal systems as possible, making it ideal for data-heavy operations like graphics rendering, 3D modeling, and scientific simulations.
The core count in each processor plays a significant role in this difference. GPUs contain far more cores than CPUs, allowing them to process multiple tasks simultaneously. The higher the number of cores, the greater the number of operations that can be processed in parallel, boosting throughput significantly.
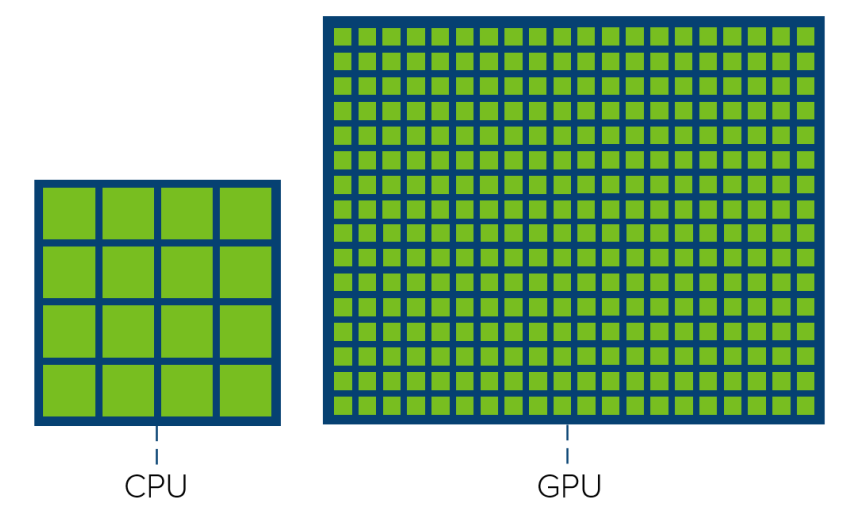
source:vmware.com
Key Architectural Differences and Similarities
While the core count is a critical difference, it’s not the whole picture. When we discuss the cores in an NVIDIA GPU, we’re referring to CUDA cores, which are made up of ALUs (Arithmetic Logic Units). It’s important to note that the terminology used for cores can vary depending on the vendor.
Despite these differences, CPUs and GPUs share several architectural similarities. Both utilize common memory constructs like cache layers, memory controllers, and global memory to manage and retrieve data efficiently. However, their design philosophies differ.
A CPU is focused on minimizing latency and optimizing single-threaded performance, while a GPU is optimized for throughput by executing many tasks at once.
CPU Package Architecture
In modern CPU architectures, the emphasis is placed on achieving low-latency memory access. This is accomplished through multiple cache memory layers, which allow the processor to quickly access frequently used data.
To give a clearer picture, let’s look at a diagram of a typical memory-focused modern CPU package. (Note: the exact layout may vary based on the vendor or model.)
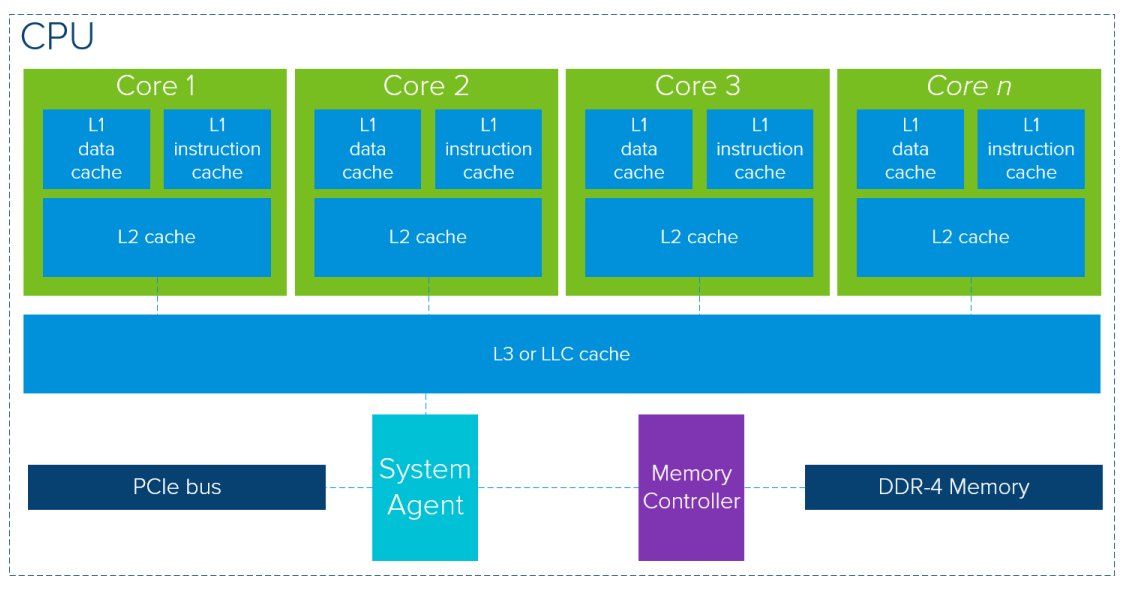
source:vmware.com
A single CPU package contains cores, each of which has separate data and instruction Layer-1 (L1) caches, supported by a larger Layer-2 (L2) cache.
Additionally, the Layer-3 (L3) cache, or last-level cache, is shared across multiple cores to ensure quick access to data that is not stored in the smaller L1 and L2 caches. When data isn’t available in the cache, it is fetched from the global DDR4 memory.
The number of cores in a CPU can range from 4 to 32, depending on the model, with clock speeds ranging from 2.5 GHz to 3.8 GHz in Turbo mode.
The L2 cache size can be as large as 2MB per core, further enhancing the processor’s ability to quickly access and process data.
Evolution of GPU Architecture
GPUs have come a long way since their inception. In the early days, graphics cards were primarily designed for rendering simple 2D graphics. But as demands for higher-quality visuals grew, so did the need for more sophisticated GPU architectures.
Early GPUs were limited to basic fixed-function pipelines, focusing solely on rendering tasks. However, with the introduction of programmable shaders by companies like NVIDIA and AMD, GPUs could handle more complex computing tasks beyond graphics.
In recent years, brands like Intel have also entered the GPU market, pushing the boundaries of GPU computing capabilities with innovative designs tailored for data centers and AI workloads.
Today’s modern GPUs are built on highly advanced architectures, utilizing parallel processing units, shader cores, and specialized hardware for ray tracing and AI acceleration.
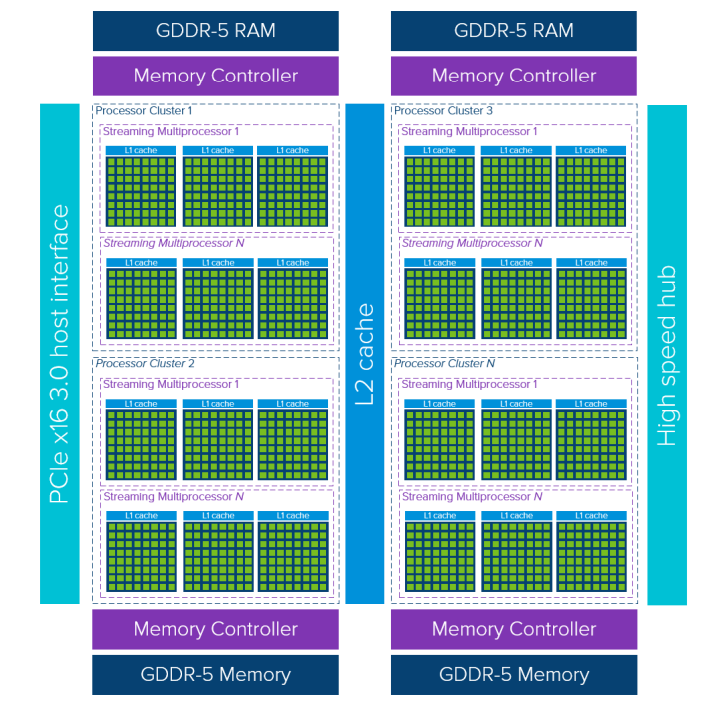
source:vmware.com
Tile-Based Rendering vs. Immediate-Mode Rendering: What’s the Difference?
One of the significant architectural distinctions in GPUs lies in how they handle rendering:
Tile-Based Rendering: Commonly used in mobile GPUs, this method breaks down a scene into smaller tiles and processes them individually. This approach optimizes memory usage and power efficiency, making it ideal for devices where power consumption is a concern.
Immediate-Mode Rendering: Predominantly used in desktop GPUs, this technique processes the entire scene in one go. It’s faster for high-performance tasks like gaming and 3D rendering but can be more demanding on memory bandwidth.
Understanding the difference between these two rendering methods helps explain why certain GPU architectures are better suited for specific tasks, whether optimizing energy efficiency in mobile devices or maximizing compute performance in gaming PCs.
Key Components of GPU Architecture
In this section, we’ll dive into the core elements that make up a GPU and explain how each part contributes to its performance.
Understanding these components helps demystify why some graphics cards are more powerful than others and what makes them suitable for specific tasks, whether it’s gaming, 3D rendering, or deep learning.
Core Elements of a GPU Explained
Every GPU is built from a collection of specialized components designed to optimize parallel processing and high-performance computing. Let’s break down the key elements:
CUDA Cores and Streaming Multiprocessors (SMs)
CUDA cores (developed by NVIDIA) are the fundamental units that perform floating-point operations in parallel. These cores are grouped into streaming multiprocessors (SMs), which are responsible for executing instructions efficiently.
The more CUDA cores and SMs a GPU has, the better its ability to handle compute-intensive tasks like AI training, machine learning, and real-time ray tracing.
Tensor Cores
Tensor cores are specialized units designed for AI and deep learning workloads, allowing for faster processing of matrix multiplications, a key component of many AI algorithms.
These cores enhance performance in tasks that require neural network training and inference, making them essential for researchers working with AI models.
Shaders and Stream Processors
Shaders are small programs that tell the GPU how to render each pixel on the screen. They handle tasks like lighting, texture mapping, and shading.
Stream processors are responsible for handling different shader types (like vertex shaders and pixel shaders), enabling the GPU to render complex scenes with smooth graphics and high detail.
VRAM (Video Random Access Memory): GDDR6X and HBM3
VRAM is the memory used by the GPU to store textures, frame buffers, and other data needed for rendering. Higher memory bandwidth translates to faster data access, improving rendering speeds and reducing latency.
The latest VRAM technologies, such as GDDR6X and HBM3 (High Bandwidth Memory), offer significantly higher memory bandwidth, which is crucial for handling 4K gaming and data-intensive workloads like 3D rendering and scientific simulations.
Cache Hierarchies
A cache is another critical part of GPU architecture. It helps store frequently used data closer to the compute units, reducing the need to fetch information from VRAM, which can be time-consuming.
A well-optimized cache hierarchy can significantly enhance a GPU’s efficiency in processing large data sets by minimizing latency.
Comparing Leading GPU Architectures in the Market
The GPU market is dynamic, with architectures constantly evolving to meet the demands of gaming, artificial intelligence (AI), and cloud computing. This analysis compares four leading GPU architectures—NVIDIA Ampere, AMD RDNA 3, Intel ARC, and ARM Mali GPUs—focusing on their compute capabilities, ray tracing cores, and performance for specific workloads.
Comparative Table of GPU Specifications
| Architecture | CUDA Cores/Shader Units | FP32 Performance | FP64 Performance | Ray Tracing Cores | Tensor Cores | TDP |
| NVIDIA Ampere | Up to 10,752 CUDA Cores | Up to 39.7 TFLOPS | Up to 1.24 TFLOPS | 2nd Gen RT Cores | Yes (AI Boost) | 320W (RTX 3090) |
| AMD RDNA 3 | Up to 12,288 ALUs | ~61 TFLOPS (FP32) | Not disclosed | Enhanced Ray Units | No | 355W (Radeon RX 7900 XTX) |
| Intel ARC | Up to 4,096 Xe Cores | ~16 TFLOPS (FP32) | Not disclosed | 1st Gen Ray Cores | No | ~200W (ARC A770) |
| ARM Mali GPUs | Varies (E.g., G710: 16 cores) | Scales for mobile | Scales for mobile | Limited (Simulated) | No | <15W (mobile) |
Key Insights and Task Suitability
1. Gaming Performance:
NVIDIA Ampere and AMD RDNA 3 excel with high computing capabilities and advanced ray tracing. NVIDIA’s 2nd Gen RT Cores offer superior performance, while AMD RDNA 3 integrates Enhanced Ray Units for competitive ray-traced graphics. AMD is noted for higher raw FP32 throughput, ideal for gamers valuing performance per dollar.
Intel ARC GPUs, while new entrants, focus on mainstream gamers with affordable ray tracing but lack the maturity of NVIDIA and AMD for ultra-high-end gaming.
ARM Mali GPUs, optimized for mobile gaming, are limited to lightweight gaming workloads.
2. AI and Machine Learning:
NVIDIA Ampere’s Tensor Cores dramatically improve AI performance, surpassing traditional Shader Units in training and inference tasks. Tensor Cores enable mixed-precision computing, critical for modern AI workloads.
AMD RDNA 3 lacks dedicated AI acceleration hardware, making it less effective for tasks like neural network training.
Intel ARC GPUs and ARM Mali GPUs do not compete in AI workloads for large-scale applications but may handle lightweight inferencing.
3. Cloud Workloads and Compute:
NVIDIA Ampere dominates with its scalability for data centers, high FP32 performance, and energy-efficient Tensor Cores, vital for cloud AI services.
AMD RDNA 3 offers significant FP32 throughput, appealing for rendering tasks in distributed cloud environments.
Intel ARC GPUs cater to niche cloud workloads but lag in compute-intensive tasks.
ARM Mali GPUs, with their energy efficiency, shine in edge computing for IoT and mobile devices but are unsuitable for high-power data center tasks.
Each GPU architecture has unique strengths tailored to specific tasks. For gaming, AMD RDNA 3 offers competitive performance per dollar, while NVIDIA Ampere remains the leader in AI and cloud workloads due to its Tensor Cores and scalability.
Intel ARC GPUs provide value for mainstream gamers, and ARM Mali GPUs excel in power-constrained environments like mobile devices.
GPU Optimization Techniques for AI and Machine Learning
Leveraging GPUs for AI and Deep Learning
In artificial intelligence (AI) and deep learning, GPUs act as powerful AI accelerators, offering superior parallel computing capabilities.
Frameworks like TensorFlow and PyTorch combine with CUDA, NVLink, and OpenACC to unlock advanced performance optimizations, enabling faster model training acceleration and inference optimization.
By leveraging techniques such as mixed precision training and advanced memory management, users can significantly enhance GPU efficiency in AI workloads.
Techniques for Optimizing GPU Compute Performance in AI Workloads
1. Maximizing GPU Utilization with Parallel Computing
GPUs are designed for parallel computing, processing thousands of operations simultaneously. Frameworks like CUDA enable optimized kernel execution, crucial for deep learning. Libraries such as cuDNN enhance matrix operations and convolutions, which are fundamental in deep learning optimization workflows. Tools like OpenACC simplify this process by allowing code annotations for automatic GPU parallelization.
For example, Training a convolutional neural network (CNN) in TensorFlow or PyTorch benefits from batch processing on CUDA-enabled GPUs, reducing training times substantially.
2. Using NVLink for Multi-GPU Scalability
NVLink provides high-bandwidth, low-latency communication between GPUs, enabling efficient scaling for large AI models. This interconnect reduces data transfer bottlenecks, particularly important for distributed deep-learning tasks.
3. Implementing Mixed Precision Training for Speed and Efficiency
Mixed precision training, which combines FP16 precision with FP32 precision, reduces memory usage while accelerating calculations. Tensor Cores on NVIDIA GPUs enable this by performing computations at reduced precision without sacrificing accuracy, significantly enhancing model training acceleration.
Example: Using AMP (Automatic Mixed Precision) in PyTorch can speed up training by up to 2x while maintaining model accuracy.
4. Inference Optimization Techniques
For real-time applications, inference optimization is essential. Reducing model complexity, quantization to lower precision (e.g., INT8), and using GPU inference libraries like NVIDIA TensorRT ensure maximum performance and minimal latency during deployment.
Memory Management: Unified Memory and FP16 Precision
1. Unified Memory for Simplified Data Handling
CUDA’s Unified Memory creates a shared address space between the CPU and GPU, eliminating manual memory transfers and reducing development complexity. This is especially useful for iterative workloads or models requiring frequent data updates.
Example: Training a GAN (Generative Adversarial Network) with large datasets benefits from Unified Memory, as it handles the movement of data between host and device transparently.
2. FP16 Precision for Training Acceleration
Using FP16 precision halves memory usage, enabling GPUs to process larger batches or train deeper models. In modern GPUs, FP16 operations are processed through dedicated Tensor Cores, offering superior AI accelerators for deep learning.
For example, Training transformers or large NLP models in TensorFlow using FP16 reduces memory constraints and speeds up convergence times by allowing higher throughput.
Optimizing GPUs for AI and machine learning involves leveraging CUDA and NVLink for scalability, using mixed precision training for speed, and managing data with Unified Memory for efficiency.
Frameworks like TensorFlow, PyTorch, and OpenACC provide robust tools to streamline these processes, enabling state-of-the-art deep learning optimization and performance gains across AI applications.
Impact of GPU Virtualization on Cloud Environments
GPU virtualization is transforming cloud computing by enabling efficient resource allocation, enhancing scalability, and improving data center efficiency. Technologies like VMware, NVIDIA GRID, GPU Passthrough, and SR-IOV are critical for creating flexible and cost-effective cloud GPU instances that cater to a variety of cloud workloads.
1. Scalable and Cost-Efficient Resource Allocation
Virtualizing GPUs allows cloud providers to divide physical GPUs into virtual GPUs (vGPUs) or assign them directly to virtual machines (VMs). This ensures high GPU utilization, reducing operational costs and enabling flexible scaling to meet varying workload demands.
For instance, with NVIDIA GRID, healthcare providers can utilize cloud GPU instances for medical imaging, reducing the need for on-premises hardware.
Similarly, industries involved in 3D rendering and animation benefit from vGPUs that allow remote collaboration on large-scale visual projects without compromising performance or budget.
2. Optimized Performance with GPU Passthrough
GPU Passthrough dedicates an entire GPU to a single VM, bypassing virtualization overhead. This is essential for performance-critical applications like game streaming and real-time AI inference.
For example, a gaming company implementing GPU Passthrough with VMware provided seamless, high-performance cloud-hosted game streaming. The setup ensured ultra-low latency and real-time graphics rendering, which is particularly important in competitive gaming scenarios.
This approach is also mirrored in applications like coding and development, where performance predictability is crucial.
3. High-Density Data Centers with SR-IOV
SR-IOV (Single Root I/O Virtualization) enhances multi-tenant cloud environments by enabling multiple VMs to share GPU resources securely and efficiently. This approach supports diverse cloud workloads like AI model training, VDI, and analytics while maintaining workload isolation.
In one case, a data center utilized SR-IOV to improve its data center efficiency, optimizing hardware usage for tasks ranging from AI analytics to scientific research in the cloud. This setup enabled the center to handle simultaneous tenant requests without performance degradation, increasing GPU utilization by 20%.
4. Cloud Workload Optimization with VMware and NVIDIA GRID
The integration of VMware and NVIDIA GRID enables efficient GPU virtualization for diverse workloads. Enterprises leverage this combination to deploy cloud GPUs for AI-driven insights and virtual desktops.
For instance, cloud solutions for medical imaging rely on these technologies to process large datasets with high precision, reducing latency and operational overhead.
GPU virtualization revolutionizes cloud computing by enabling scalable, cost-effective solutions for complex cloud workloads. Technologies like VMware, NVIDIA GRID, GPU Passthrough, and SR-IOV facilitate efficient resource allocation while meeting the demands of sectors like gaming, AI analytics, 4K video playback, and healthcare.
By optimizing hardware usage and increasing data center efficiency, GPU virtualization continues to reshape the future of cloud computing.
Future Trends in GPU Development
The Future of GPU Architecture
The field of GPU architecture is evolving rapidly, driven by demand for higher performance, scalability, and energy efficiency. Future developments focus on AI accelerators, Quantum GPUs, and Exascale Computing, introducing groundbreaking advancements in next-gen GPU architectures.
These emerging GPU technologies promise to redefine computing capabilities by delivering scalable computing resources and low-power GPU designs for diverse applications like AI, quantum simulations, and immersive graphics.
Key Innovations Shaping GPU Architecture
1. Advanced AI Accelerators for Intelligent Workloads
AI accelerators in GPUs are becoming increasingly specialized to handle complex AI models. Tensor Cores and AI-dedicated hardware are evolving to enhance model training acceleration and inference tasks.
Future designs will push the boundaries of low-power GPU designs, making them more suitable for edge AI applications, such as robotics and autonomous vehicles.
For example, advancements in exascale computing will integrate enhanced AI processing, enabling breakthroughs in real-time AI applications like medical imaging in cloud-based environments.
2. Quantum GPUs for Next-Generation Simulations
Quantum GPUs represent a fusion of classical and quantum computing, designed for specialized applications like cryptography, molecular modeling, and quantum chemistry. These next-gen GPU architectures will offer hybrid quantum-classical capabilities, enabling researchers to simulate quantum systems at unprecedented scales.
In exascale computing, these GPUs will support high-fidelity simulations, creating opportunities for advancements in fields like scientific research and next-generation secure communications.
3. Enhanced Ray Tracing and Graphics Rendering
The future of GPU architecture includes significant improvements in ray tracing technology. Enhanced RT Cores, combined with AI-driven denoising, will allow for real-time, photorealistic rendering in applications like gaming, VFX, and virtual reality.
Emerging GPU technologies will focus on scalable compute resources that enable seamless rendering across devices, further supporting demanding workloads like 3D rendering and animation.
4. Energy-Efficient Designs for Sustainability
As energy efficiency becomes critical, low-power GPU designs will incorporate advanced cooling solutions, power management systems, and fabrication processes (e.g., 3nm nodes). These designs will ensure optimal performance per watt, particularly important for exascale computing, where power consumption is a significant consideration.
By prioritizing energy efficiency, future GPUs will power workloads like coding and development on integrated GPUs, balancing computational strength with sustainable energy use.
Real-World Applications of Modern GPUs
From Gaming to Scientific Computing: Where GPUs Excel
Modern GPUs have transformed industries by delivering powerful solutions for compute-intensive applications, advanced rendering pipelines, and large-scale data analysis. From ray tracing in gaming to High-Performance Computing (HPC) for scientific simulations, GPUs drive innovation across fields like healthcare, finance, and automotive. Key technologies such as DLSS (Deep Learning Super Sampling) further enhance their relevance by balancing performance and visual fidelity in demanding tasks.
GPU Use Cases Across Industries
1. Gaming: Real-Time Rendering and Enhanced Visuals
GPUs have revolutionized gaming by introducing ray tracing for lifelike lighting, shadows, and reflections. Paired with DLSS, gamers experience high-resolution graphics without compromising performance.
Rendering pipelines powered by modern GPUs streamline complex graphical processes, enabling immersive experiences. For example, GPUs drive cloud-based gaming platforms, offering seamless real-time rendering for users across devices.
2. Healthcare: Accelerating Medical Imaging and Research
GPUs power compute-intensive applications like MRI reconstruction and CT scan analysis, reducing processing times while improving diagnostic accuracy. In genomics, GPUs enable faster sequencing and analysis, advancing personalized medicine.
High-Performance Computing (HPC) in healthcare has also facilitated advancements in drug discovery through molecular modeling and simulations. These GPU-driven applications are essential for innovation in scientific simulations.
3. Finance: Data Analysis and Risk Management
In the finance sector, GPUs accelerate data analysis, enabling real-time risk management and fraud detection. By handling large datasets efficiently, GPUs empower institutions to make faster, data-driven decisions.
Financial models and predictive analytics rely on the parallel processing capabilities of GPUs, especially for tasks like portfolio optimization and market simulations.
4. Automotive: AI and Autonomous Vehicles
GPUs are at the core of autonomous vehicle development, handling the heavy processing required for sensor fusion, real-time object detection, and decision-making.
In addition to enabling autonomy, GPUs optimize rendering pipelines for vehicle simulations, helping manufacturers design safer and more efficient cars. Industries also leverage GPUs for 3D rendering and animation, improving design workflows
Modern GPUs excel in diverse industries, offering cutting-edge solutions for real-time rendering, scientific simulations, and other compute-intensive applications.
Technologies like ray tracing, DLSS, and HPC showcase their versatility, driving innovation across gaming, healthcare, finance, and automotive sectors. These GPU use cases illustrate the transformative potential of GPUs in reshaping industries and enhancing efficiency.
Best Practices for Choosing the Right GPU
When selecting the ideal Graphics Processing Unit (GPU), the decision depends on your specific use case. Whether you’re a gamer, an AI researcher, or managing a data center, understanding the factors that matter can make all the difference. Here’s a detailed guide to help you make the best choice.
Selecting a GPU for Your Needs
1. Gaming GPUs: Power Meets Performance
For gamers, the focus should be on the price-to-performance ratio and TDP efficiency to ensure the GPU can handle high-quality visuals without overheating or consuming excessive power.
High-performance options like the RTX 5090 and Radeon RX 7900 stand out for delivering exceptional frame rates at 4K resolution. When searching for the best GPU for gaming, consider factors like VRAM, clock speeds, and ray-tracing capabilities to get a seamless experience in demanding titles.
2. AI GPUs: Tailored for Machine Learning and Research
If your focus is on AI GPU recommendations, look for GPUs optimized for parallel processing and compute power. Products like NVIDIA’s RTX 5090 or Intel Xe GPUs can accelerate deep learning models while maintaining efficiency.
Key considerations include multi-GPU configurations and high bandwidth memory to ensure scalability for larger datasets.
3. GPUs for Cloud and Data Centers
In computing GPU for data centers, the emphasis shifts to efficiency and workload handling. GPUs like the Radeon RX 7900 offer robust performance for cloud environments, balancing computational power with thermal management.
Prioritize TDP efficiency and support for multi-GPU configurations to maximize throughput in demanding applications like cloud computing and virtualization.
Key Factors to Consider
- Compatibility: Ensure the GPU fits within your system’s thermal and physical constraints. High-end GPUs like the RTX 5090 might require enhanced cooling solutions.
- Performance Needs: Gamers prioritize frame rates, while researchers focus on floating-point operations per second (FLOPS).
- Budget: Strike a balance between performance and cost by comparing the price-to-performance ratio across options like the Radeon RX 7900 and Intel Xe GPUs.
- Future Proofing: Select a GPU with features like ray tracing and DLSS for gaming or tensor cores for AI to stay ahead of the curve.
By assessing your unique requirements and evaluating these factors, you can confidently choose a GPU that meets your needs without overspending.
Conclusion
Understanding GPU architecture is essential for maximizing the potential of your hardware. Whether you’re focused on gaming, AI research, or cloud-based workloads, the distinction between CUDA cores, Tensor cores, and architectural features like GPU virtualization plays a pivotal role in performance.
The GPU’s core design philosophy—optimized for parallel processing—contrasts sharply with the CPU’s focus on serialized task execution and low-latency operations. With entities like the NVIDIA RTX 5090, AMD Radeon RX 7900, and Intel Xe GPUs, you have access to a range of solutions tailored for specific needs, from gaming to AI model training and data center workloads.
If you’re planning to invest in new hardware, consider factors like price-to-performance ratio, TDP efficiency, and multi-GPU configurations to ensure you’re choosing the best option for your requirements.
Frequently Asked Questions
CUDA cores are fundamental to NVIDIA GPUs and are designed for general-purpose parallel computing tasks. They handle operations like graphics rendering, physics simulations, and basic computations in AI workloads.
Tensor cores, on the other hand, are specialized cores found in NVIDIA’s RTX GPUs, optimized for AI-specific tasks such as deep learning and matrix operations. These cores accelerate operations like matrix multiplications (essential in neural networks) by performing them more efficiently than traditional CUDA cores. Tensor cores are invaluable for AI researchers looking to train or infer large models quickly.
GPU virtualization enables multiple users or applications to share the same physical GPU hardware. This technology is critical in cloud computing environments, where optimizing resource allocation is a priority.
With GPU virtualization, workloads like graphics rendering or AI model training can be distributed across virtual GPUs, reducing operational costs while maintaining high performance.
However, this approach can sometimes lead to reduced throughput compared to dedicated GPUs, especially in tasks requiring intense computational resources.
For AI model training, you’ll want a compute GPU with robust parallel processing capabilities, high memory bandwidth, and support for Tensor cores. Popular options include:
- NVIDIA RTX 5090: Ideal for large-scale deep learning and complex simulations.
- AMD Radeon RX 7900: A strong alternative with excellent computing power and cost efficiency.
- Intel Xe GPUs: Emerging contenders in AI, offering competitive performance at lower power consumption.
Consider factors like multi-GPU configurations, price-to-performance ratio, and compatibility with AI frameworks like TensorFlow or PyTorch to ensure the GPU meets your requirements.


