
Introduction
The rapid advancement of deep learning has led to increasingly complex and larger models, demanding significant computational resources and memory.
Graphics Processing Units (GPUs) have become the cornerstone for training deep learning models, commonly used in frameworks like TensorFlow and by companies such as DeepMind. They also power platforms like Google Cloud AI and AWS EC2 Instances with their parallel processing capabilities. The innovations in GPU architecture underpin their ability to handle such intensive computations efficiently.
However, GPUs are often constrained by their limited memory capacity, creating a bottleneck for training larger and more sophisticated deep neural networks (DNNs). This memory limitation hinders the exploration of deeper and wider models that could potentially achieve higher accuracy.
To overcome these challenges, there is a critical need for efficient memory management techniques that can optimize the utilization of available GPU memory and enable the training of large-scale models.
This article explores two key approaches to tackle this problem: SmartPool, a memory pool management strategy, and DrGPUM, a novel object-centric GPU memory profiling tool.
SmartPool focuses on optimizing memory allocation during the training process, while DrGPUM provides insights to identify and address memory inefficiencies, guiding optimization efforts.
The Problem: GPU Memory Bottleneck in Deep Learning
Deep learning models, particularly DNNs, have a voracious appetite for memory, requiring substantial resources for training. Frameworks like PyTorch and TensorFlow, along with innovations from companies like OpenAI, have further expanded their capabilities and memory demands.
The training algorithms involve numerous large matrix operations that consume substantial GPU memory.
The trend towards deeper and wider networks, exemplified by groundbreaking models like DeepMind’s AlphaGo and AlphaFold, further exacerbates the memory requirements, often exceeding the capacity of a single GPU.
For instance, the AlexNet model was trained on two GPUs, while the larger VGG network required a 4-GPU system. Furthermore, cutting-edge models, such as a trillion-parameter model like GPT-4, require up to 320 high-end NVIDIA A100 GPUs.
These memory demands pose a significant challenge to the scalability of deep learning, particularly in cloud-based environments like Google Cloud AI and AWS, where resource optimization is critical to handling large-scale models. Existing memory management techniques, such as buffering and paging, model compression, and memory swapping, often come with limitations:
- Coarse-grained buffering and paging are not optimal for deep learning due to the significant variation in the sizes of variables.
- Model compression techniques can decrease accuracy or introduce quantization errors.
- Memory-swapping methods frequently require manual intervention.
These limitations underscore the necessity for automated and efficient memory optimization strategies that can be seamlessly integrated into existing deep learning systems.
SmartPool: Optimizing Memory Allocation
SmartPool is a memory pool management approach designed to optimize memory allocation within a GPU memory pool.
It leverages the iterative nature of deep learning training to analyze the lifetime and size of variables, which is typically stable across middle iterations, enabling more informed memory allocation.
The core idea of SmartPool is that memory can be shared between variables whose lifetimes do not overlap.
The memory allocation problem in deep learning is an NP-complete problem called Dynamic Storage Allocation (DSA), where the goal is to allocate memory for a sequence of objects with varying sizes and lifetimes.
SmartPool uses a heuristic algorithm to solve the DSA problem by transforming it into an offline problem. This approach complements frameworks like TensorFlow and PyTorch, which benefit from memory optimization during model training.
This is achieved by collecting variable lifetimes and sizes in the initial iterations and applying memory optimization in subsequent iterations.
The heuristic algorithm makes allocation decisions by creating a weighted graph, in which the nodes represent the variables, and the weights of the edges represent the degree of overlap in the lifetimes of the variables.
SmartPool employs a fine-grained approach to memory sharing, allowing variables with non-overlapping lifetimes to use the same memory space. This approach maximizes memory utilization and reduces memory fragmentation, as one large variable may share the same memory space with several smaller variables and vice versa.
Such techniques ensure that GPUs operate within safe thermal ranges, maintaining a normal GPU temperature during high-intensity operations.
Unlike Nvidia’s default memory pool, CnMem, which does not optimize for deep learning training, SmartPool achieves a low competitive ratio, bringing the actual memory consumption closer to the theoretical minimum.
Experimental results show that SmartPool can reduce memory footprint by up to 13.3% compared to CnMem while maintaining a low time complexity of O (log n), where n is the number of variables.
AutoSwap: Reducing Memory Load
AutoSwap is an automatic mechanism for reducing memory load on the GPU. It does this by swapping variables that are not currently in use from GPU memory to CPU memory and then swapping them back to the GPU when needed. This approach is designed to be transparent to end users, requiring no manual intervention.
AutoSwap implements a priority-based scheduling system, using several metrics to determine which variables to swap. These priority scores include:
- Area of Absence (AOA): The total time a variable is absent from the GPU memory.
- Duration of Absence (DOA): The time interval for which a variable is not in use.
- Weighted Duration of Absence (WDOA): The DOA multiplied by a weight, which depends on the size of the variable.
- Submodular Weighted Duration of Absence (SWDOA): A variant of WDOA designed to capture the diminishing returns of swapping large variables.
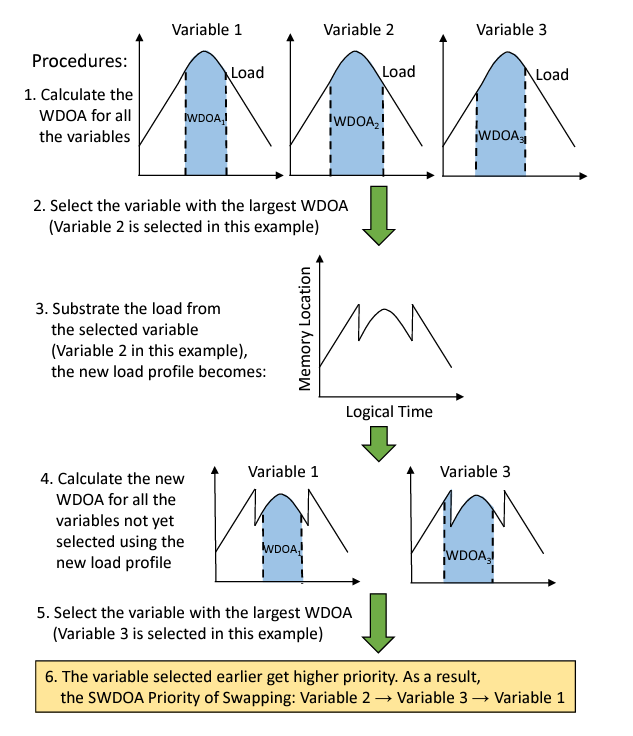
image source:arxiv.org
To optimize swapping schedules, AutoSwap uses Bayesian Optimization (BO), which tunes the weights of different priority scores, minimizing communication overhead. Swapping is done by copying the data to the CPU, and then when needed, copying the data back to the GPU.
AutoSwap minimizes communication overhead by swapping data using separate cudaStreams parallel to the computation cudaStream, enabling concurrent operations.
AutoSwap leverages the iterative nature of deep learning to identify variables suitable for swapping, such as feature maps in frameworks like Keras, MXNet, or TensorFlow, which are needed during backward propagation.
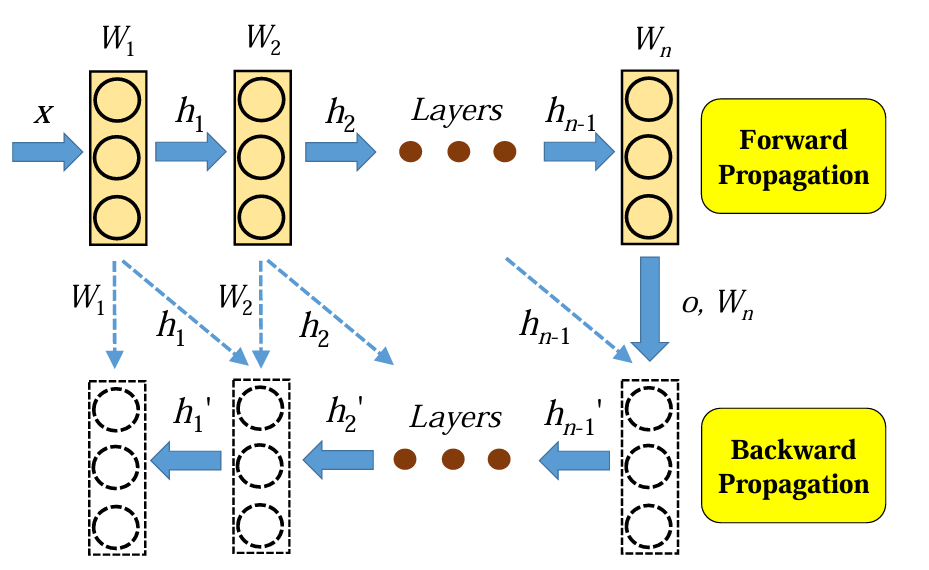
image source:arxiv.org
The algorithm filters out tiny variables and variables whose lifetimes do not span the peak memory usage, to make the best swapping choices.
AutoSwap has demonstrated the ability to reduce memory costs by up to 34.2% without incurring communication overhead.
Combining SmartPool and AutoSwap
SmartPool and AutoSwap are designed to be orthogonal approaches that can work in tandem to further reduce the memory footprint.
SmartPool is a memory pool management strategy, and AutoSwap is a memory load management strategy. Because SmartPool is built on top of the sequences of malloc and free calls, SmartPool is created after AutoSwap is created.
The combined effect of SmartPool and AutoSwap results in a significant reduction in memory usage, enabling the training of larger models. Experimental results show that this combined approach can reduce the memory footprint by up to 1/3 without increasing training time, and up to 60% with less than 15% overhead.
The performance of the combined approach is scalable, showing considerable memory savings across different network depths and batch sizes.
The combined approach has been compared with other memory reduction baselines, including:
- MXNet-memonger: This method uses memory sharing, in-place operations, and trading computation for memory.
- GeePS: This approach uses a GPU-specialized parameter server to enable scalable deep learning on distributed GPUs.
- SuperNeurons: This framework provides options to recompute and/or swap, with swapping restricted to convolution layers.
Compared to these methods, the combined approach offers several advantages:
- Adjustability: It allows users to adjust the percentage of footprint reduction within a wide range, preventing excessive memory swapping and communication.
- Transparency and Automation: It operates transparently, automatically starting in the early iterations without requiring user intervention.
- Low Overhead and Scalability: It provides low overhead while scaling effectively across various DNN types, depths, batch sizes, and footprint reduction percentages.
DrGPUM: A Memory Profiling Tool
While SmartPool and AutoSwap focus on memory management, DrGPUM offers a complementary approach by providing a detailed analysis of memory usage patterns.
DrGPUM, an innovative object-centric GPU memory profiler, correlates data objects with GPU APIs to deliver actionable optimization insights.
It aligns with tools like NVIDIA’s Nsight Systems and memory profilers used in TensorFlow and PyTorch, offering compatibility across popular deep-learning platforms.
Unlike existing GPU profilers that often monitor memory usage from a macroscopic view, DrGPUM provides both object-level and intra-object analyses.
This means that it tracks memory usage both by looking at data objects as a whole, and at individual elements within those data objects.
DrGPUM offers several key advantages over existing profilers:
- Object-centric Analysis: It correlates memory usage with data objects and GPU APIs.
- Multi-Scale Analysis: It performs both macroscopic object-level analysis and microscopic intra-object analysis.
- Actionable Insights: It provides intuitive program insights and suggestions for optimization.
- Application Independence: It works on fully optimized and unmodified GPU binaries without requiring source code modifications.
- Detection of Unique Inefficiencies: DrGPUM detects inefficiencies, such as early/late deallocation, redundant/unused allocation, memory leaks, temporary idleness, dead writes, overallocation, non-uniform access frequency, and structured access.
- Liveness analysis: DrGPUM provides a view of data object lifecycles, showing when a data object is allocated and deallocated.
DrGPUM’s workflow consists of the following key stages:
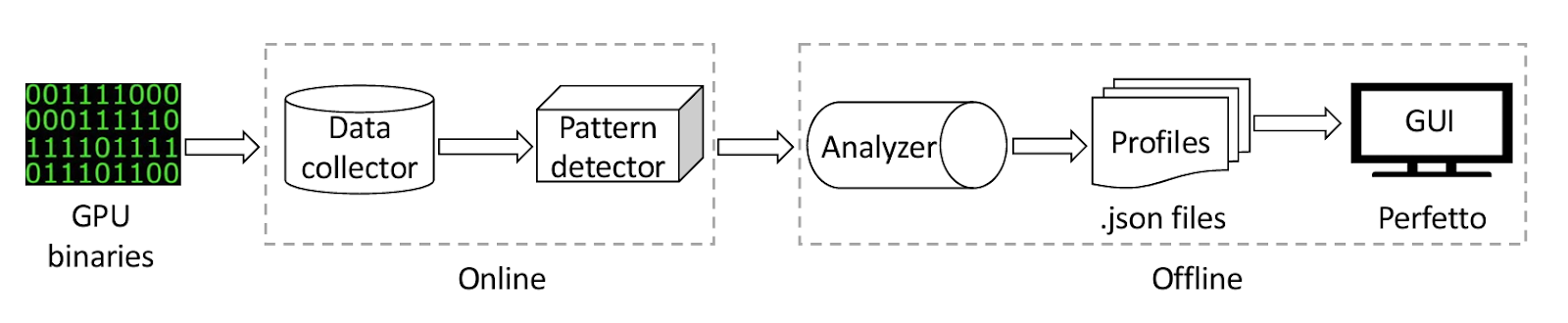
image source: par.nsf.gov
- Online data collection: It uses NVIDIA’s Sanitizer API to intercept GPU API calls and memory instructions, recording object-level and intra-object information, as well as call paths.
- Online pattern detection: It analyzes the collected data to detect patterns of memory inefficiencies and suggests optimization strategies. Pattern detection is partially offloaded to the GPU to reduce CPU-GPU traffic.
- Offline analysis: It extracts line mapping information from executables and libraries to associate inefficiencies with source code.
- Offline GUI: It presents the analysis results through a user-friendly web-based graphical interface for visualization, which shows the lifetimes of data objects, a topological order of GPU APIs, and inefficiency patterns.
DrGPUM builds a dependency graph based on the temporal order of memory operations, taking into account dependencies between GPU APIs in multi-stream applications.
It also includes a mechanism to handle custom memory APIs used by deep learning frameworks like PyTorch, by registering callbacks through the framework’s debugging utilities.
To reduce overhead, DrGPUM uses adaptive techniques for object-level and intra-object analyses, such as kernel sampling and whitelisting.
DrGPUM has been used to optimize several applications. Here are some of them:
- SimpleMultiCopy: DrGPUM identified that the data object d_data_out1 was allocated too early, suggesting a later allocation to save memory. Also, other data objects were found to be temporarily idle or deallocated too late. Fixing these issues reduced peak memory usage by 50%.
- Darknet: DrGPUM found a dead write pattern in the array l.weights_gpu, which was being initialized twice. By removing the redundant initialization, memory peak was reduced by 83%.
- Polybench/GramSchmidt and BICG: DrGPUM found structured access and redundant allocation patterns, allowing for memory savings.
- MiniMDock: DrGPUM identified an overallocation pattern with a large data object that had a low usage rate, reducing memory usage by 64%.
- Laghos: DrGPUM confirmed and optimized a late deallocation pattern with two member variables of a class, which together reduced peak memory usage by 35%.
DrGPUM was compared with other profiling tools such as ValueExpert and Compute Sanitizer. ValueExpert targets value-aware memory inefficiencies while DrGPUM targets value-agnostic ones, therefore ValueExpert failed to detect most of the inefficiencies found by DrGPUM.
Table: DrGPUM vs. state-of-the-art tools – whether the inefficiencies detected by DrGPUM could be detected by other tools.
| Inefficiency patterns | DrGPUM | ValueExpert | Compute Sanitizer |
|---|---|---|---|
| Early Allocation | Yes | No | No |
| Late Deallocation | Yes | No | No |
| Redundant Allocation | Yes | No | No |
| Unused Allocation | Yes | Yes* | No |
| Memory Leak | Yes | No | Yes |
| Temporary Idleness | Yes | No | No |
| Dead Write | Yes | No | No |
| Overallocation | Yes | No | No |
| Non-uniform Access Frequency | Yes | No | No |
| Structured Access | Yes | No | No |
Compute Sanitizer was able to detect memory leaks, however it does not correlate data objects with GPU APIs and also misses many inefficiencies.
Evaluation and Results
The effectiveness of SmartPool, AutoSwap, and the combined approach has been demonstrated through comprehensive experiments on various DNN models and datasets.
These methods were evaluated for memory reduction, communication overhead, and scalability.
The experimental setup included different GPU platforms, including NVIDIA RTX 3090 and A100 GPUs, and various benchmarks such as Rodinia, PolyBench, XSBench, and applications like PyTorch, Darknet, Laghos, and MiniMDock.

source: par.nsf.gov
The results show that:
- SmartPool effectively optimizes the memory pool, reducing fragmentation and achieving a better competitive ratio.
- AutoSwap significantly reduces memory load by automatically swapping out unused variables, with minimal overhead.
- The combined approach of SmartPool and AutoSwap provides the most significant reduction in memory footprint, allowing for training larger models with greater efficiency. The combined approach can reduce up to 1/3 of the memory footprint without increasing training time, and up to 60% with less than 15% overhead.
- These methods are highly scalable, working efficiently with different network depths and batch sizes.
- DrGPUM identifies various memory inefficiencies in different applications, such as SimpleMultiCopy, Darknet, MiniMDock, and others. It then provides optimization suggestions that lead to significant peak memory reductions.
- DrGPUM incurs low overhead due to its optimization techniques, including kernel sampling, kernel whitelisting, and offloading some analysis to the GPU.

source: par.nsf.gov
Conclusion
In conclusion, SmartPool and AutoSwap offer effective strategies for optimizing GPU memory usage in deep learning. SmartPool improves memory allocation by using information about variable lifetime and sizes, while AutoSwap reduces memory load by automatically swapping out unused variables.
These methods are designed to be transparent to the user can be used without manual intervention, and can be combined to achieve even greater memory savings. Additionally, DrGPUM serves as a valuable tool for identifying memory inefficiencies by providing detailed object-level and intra-object analyses.
Combining SmartPool, AutoSwap, and DrGPUM insights helps practitioners minimize memory footprints, enabling the training of larger, more complex models while overcoming GPU memory limitations.
Future work includes extending the solutions for applications that have slight variations in their iterations, exploring memory reduction in a distributed environment, and adapting these approaches to other memory-intensive applications with iterative patterns, such as large-scale K-Means running on GPUs.
Additionally, further work will include enabling DrGPUM to support TensorFlow, and exploring memory inefficiencies beyond GPU code, into the CPU-GPU interactions.


